Meetings in 2017
- 2017-DEC-06 Feature Selection Methods for Classification in Machine Learning, by Brendan Cord Lethebe, Biostatistician, Clinical Research Unit, University of Calgary
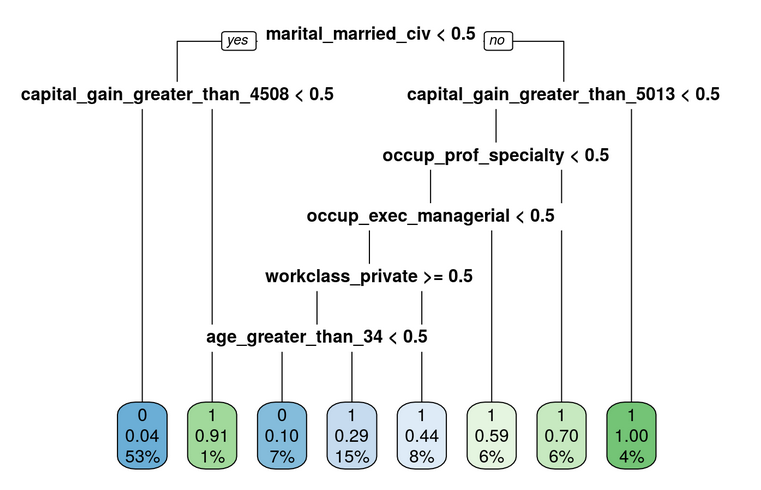
Using machine learning feature selection methods for classification purposes. Methods used will be: Forward Stepwise Logistic Regression, LASSO logistic regression, the C5.0 decision tree, Rpart Decision trees, and CHAID decision trees. Learning to use multiple methods to create interpretable classifiers. Also, simple bootstrapping and cross-fold validation methods will be implemented.
- 2017-NOV-22 Time-series Prediction with R
In this session, we will go through a public data set and learn how to plot the time series, how to adjust trend and seasonality in the time series and how to use the Forecast library to predict the time series.
- 2017-NOV-08 Intermediate Data Cleaning Techniques using R
This lecture provides a practical guideline for writing data cleaning script. We start with understanding variable types and measurement scale for analysis. In the first session (30 mins), we will explore indexing and matching techniques, data type conversion and recoding, and string manipulation and standardization in terms of technical correctness of data. In the second session (30 mins), techniques for handling missing and special values and determining outliers are explored in terms of data consistency. If time is permitted, a brief introduction to imputation technique will be provided.
- 2017-OCT-25 Examples of developing application using R
R has been used in various areas as well as many different ways. In this talk, three types of examples in developing application will be presented. These include using R as a standalone program, a part of modules, and a main procedure. In addition, the common goal of these examples is to reduce the human resource and to improve the performance.
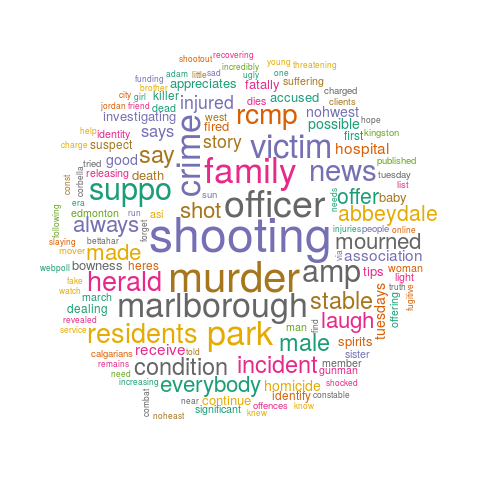
A visualization technique for text data will be explored. We start with extracting data from Twitter and discuss how to clean up the text for analysis. New R users can learn the basics of regular expression. Once stop words are removed, a word cloud will be generated.
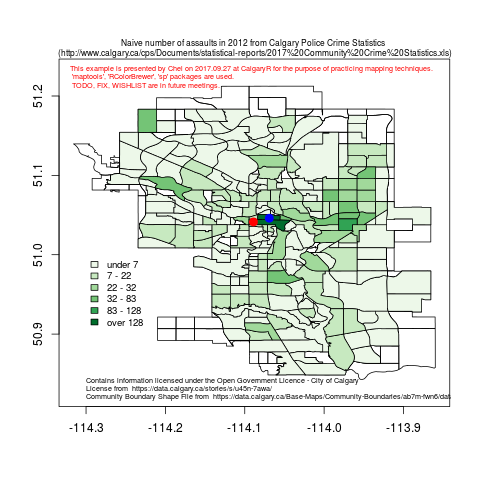
We continue to work with the Calgary Police Crime Statistics. We will reformat the data according Hadley Wickham’s “Tidy Data” methodology and add 2017 Calgary census data to the existing dataset, and perform some more exploratory data analysis.
This workshop discuss the potentials and challanges of working with the Calgary Policy Crime Statistics which are publicaly available. A problem of mapping crime incidence is considered. Some useful R functions and techniques needed for working this problem are shared. Note that the basic types of data objects are briefly reviewed for new R learners. Finally, the problem of data quality assurance, importance of data dictionary, and issues on deriving information from data are addressed for further analysis. Download the R codes
- 2017-SEP-13 Social Gathering 2017 in Calgary
Calgary R Users Group is planning to have a social gathering on the evening of September 13 for brief talks and discussion on topics in data science. Everyone is welcome. It is a good opportunity to meet other R users.
This website is built since 2017-09-01 by using Rmarkdown. Note that Information noted here comes with ABSOLUTELY NO WARRANTY and the contents are frequently changed without any notifications.